

概要
専門分野のチャットボットを作るシリーズの第2回目!
前回のおさらい
✅自社開発している専門的で複雑なソフトのチャットボットを作りたい。
✅しかし専門的すぎて精度を上げるのが難しそう。
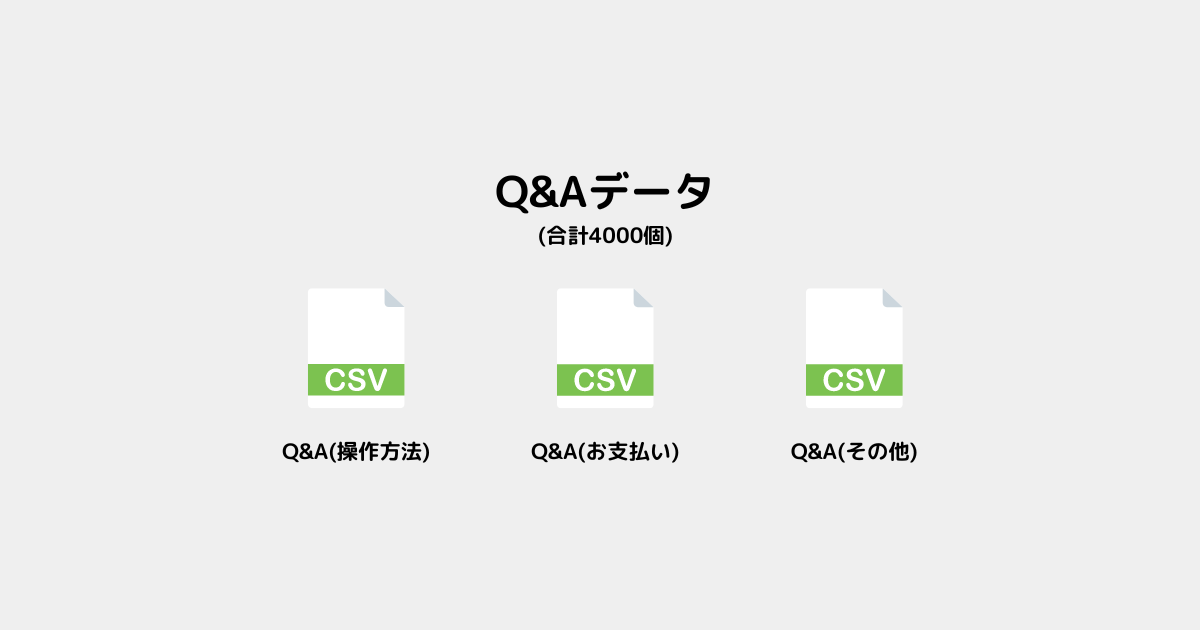
✅独自データは「Q&A 4000個」「解説書 4000ページ」を持っている。
今回やること
インデックスの内容を変えることで精度の向上を試みる✅
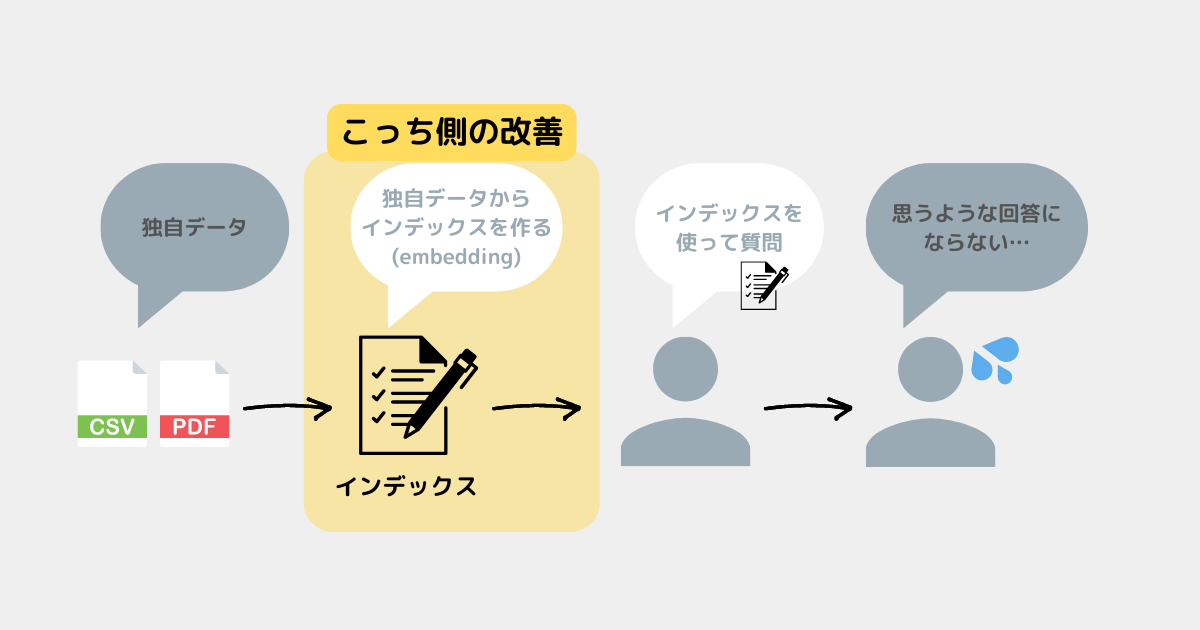
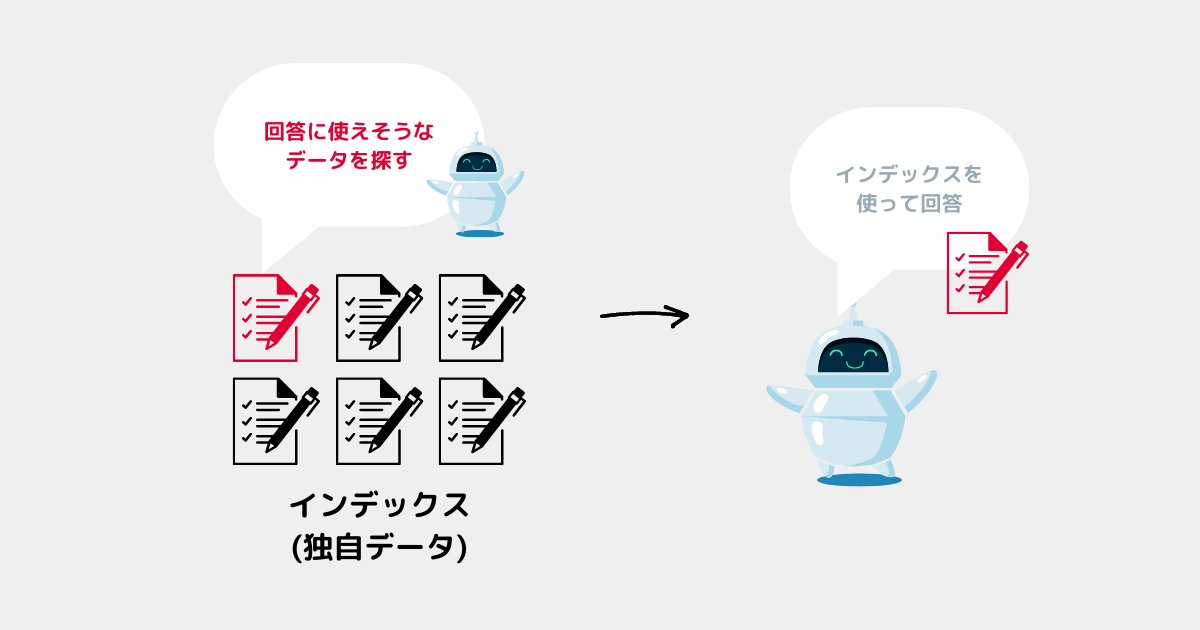
インデックスとは
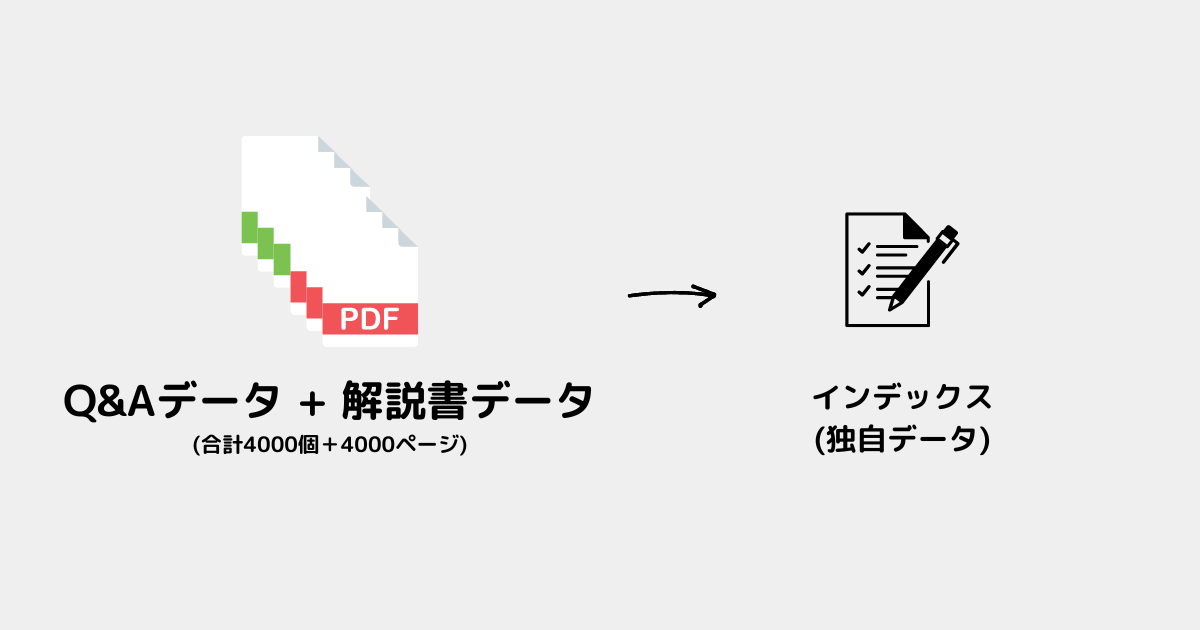
前提として独自データを扱うには、独自データからインデックスを作成する必要がある✅
イメージ図
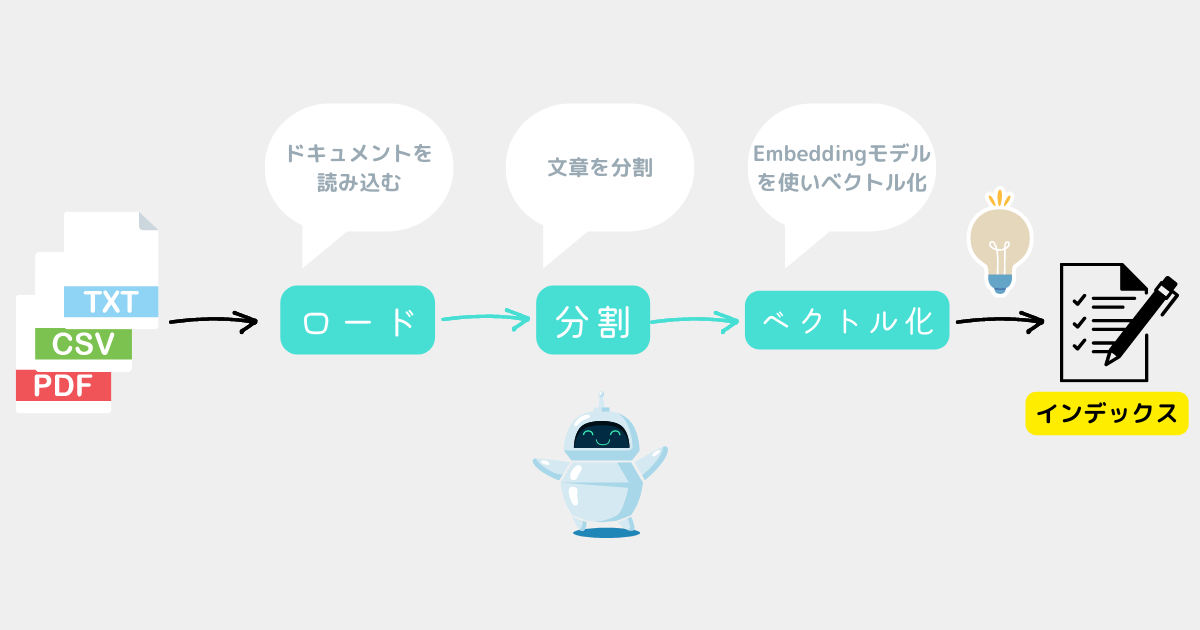
今回はインデックスについて理解している前提で進める。
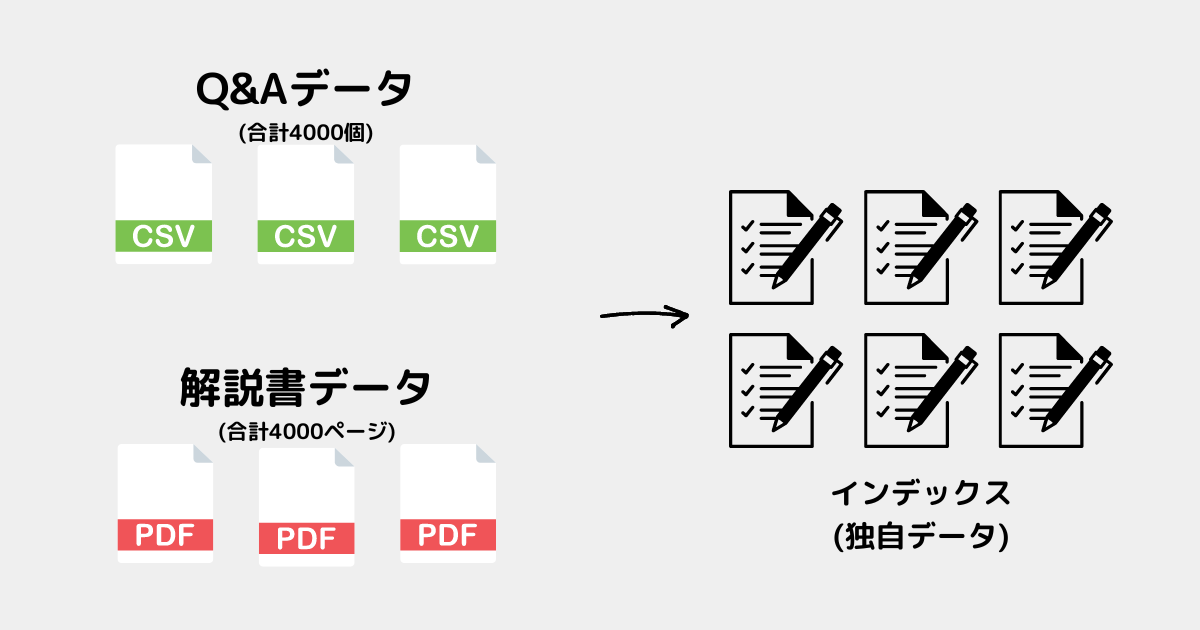
インデックス化するデータ
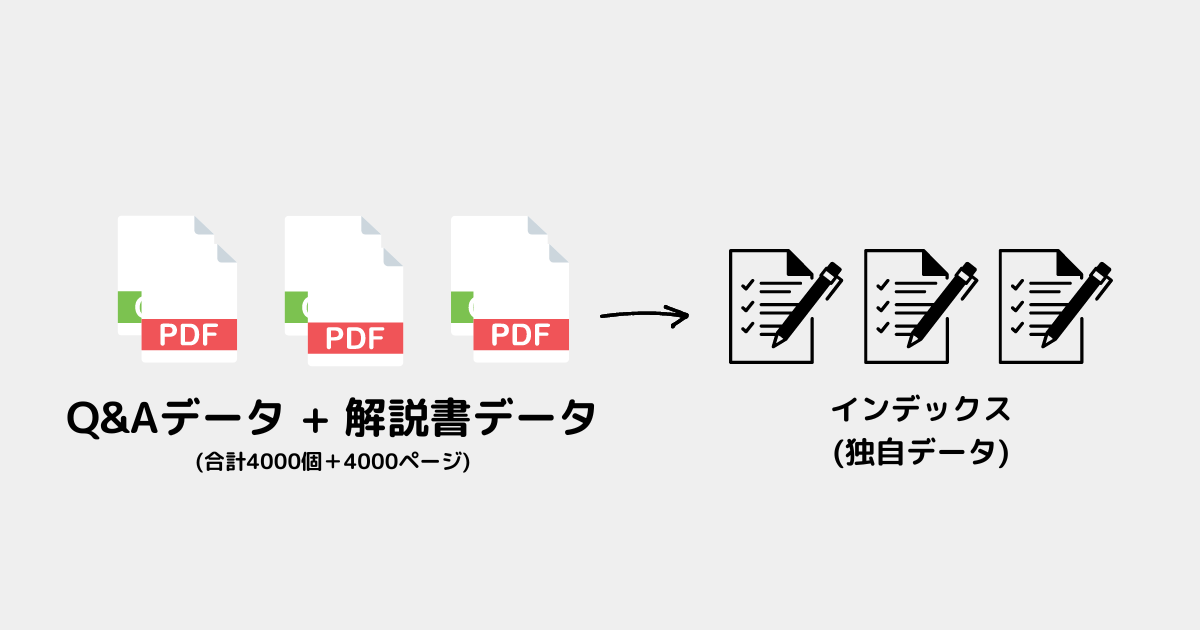
今回はCSV(Q&Aデータ)とPDF(解説書データ)をインデックス化する✅
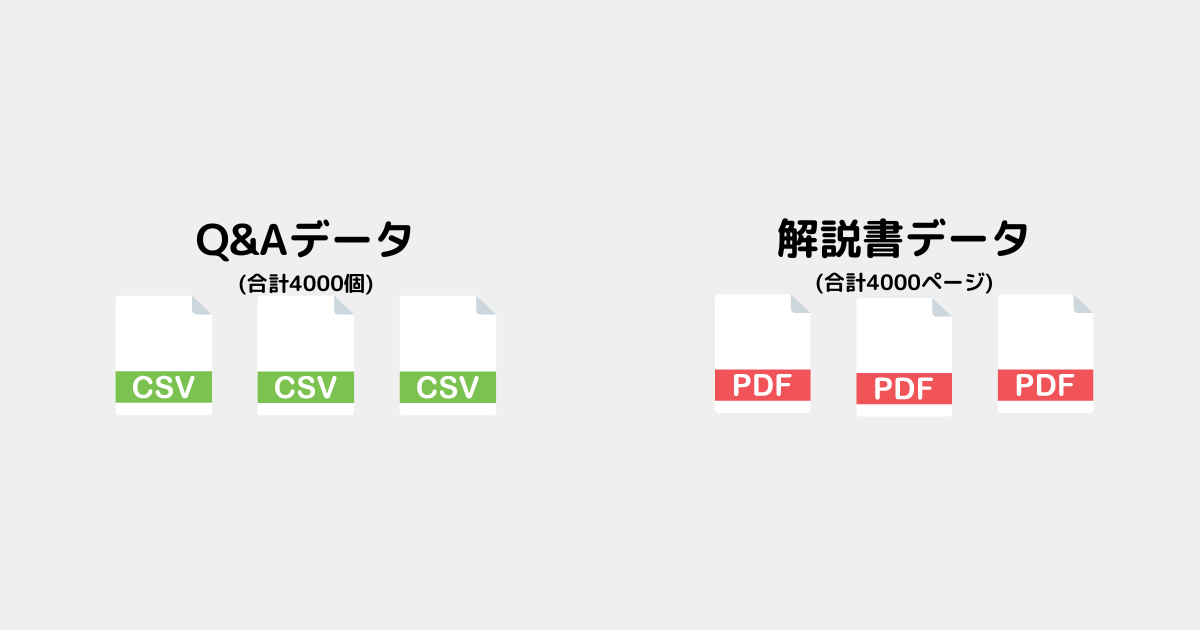
図は簡略化しているが、実際はCSV10個、PDF10個もある。
結論ファースト
✅独自データが複雑であるほど、インデックスを工夫する価値がありそう
✅大量の独自データを1つのインデックスにまとめると、適切に独自データから回答を見つけられなかった
✅カテゴリーごとにインデックスを分けるのもあり(エージェントと併用する)
✅重複したデータはまとめておくとよさそう
精度向上のために試したこと
前提として「どのようにインデックス化するのがベストか?」は持っている独自データによって変わりそう✅
そもそもインデックス作成で試行錯誤する必要があるか
もし独自データが「Q&A10題だけ」などのシンプルなデータなら、何も考えずインデックスを作ってもあまり精度は変わらなさそう💭
今回は癖の強い独自データを扱うので工夫する価値があると考えた✅
- データが大量(Q&A4000題、解説書4000ページ)
- ファイルが分かれている(合計20個のファイル)
- ファイル形式が複数ある(CSVとPDF)
- CSVとPDFで一部内容が重複している(言い回しが違うけど同じような内容)
- 専門用語が多数出てくる
イメージ

インデックス比較結果
先にインデックスごとの比較結果を示す✅
| 案 | インデックス | 精度 | 結果 |
|---|---|---|---|
| 案1 | そのまま使用 | ❌ | どのファイルに答えがあるか見つけられない。 |
| 案2 | CSVを1つ、PDFを1つにまとめる | ❌ | どのファイルに答えがあるか見つけられない。 |
| 案3 | すべてのファイルを1つにまとめる | ❌ | 独自データの中から回答を見つけられない。 |
| 案4 | CSVとPDFの同じカテゴリーを1つにまとめる | 🔺 | 少し精度がよくなったが、どのファイルに答えが見つけられないことがある。 |
案1:そのまま使用
✅合計20個のファイルをそのまま使う
(画像は簡略化のため6個にしている)
✅質問実行プログラムのイメージ
✅所感
| メリット⭕️ | デメリット❌ | 精度 |
|---|---|---|
| − | どのファイルに答えがあるかAIに探してもらうのが難しく、関係ないデータを使ってしまうことが多い。 | ❌ |
✅考察
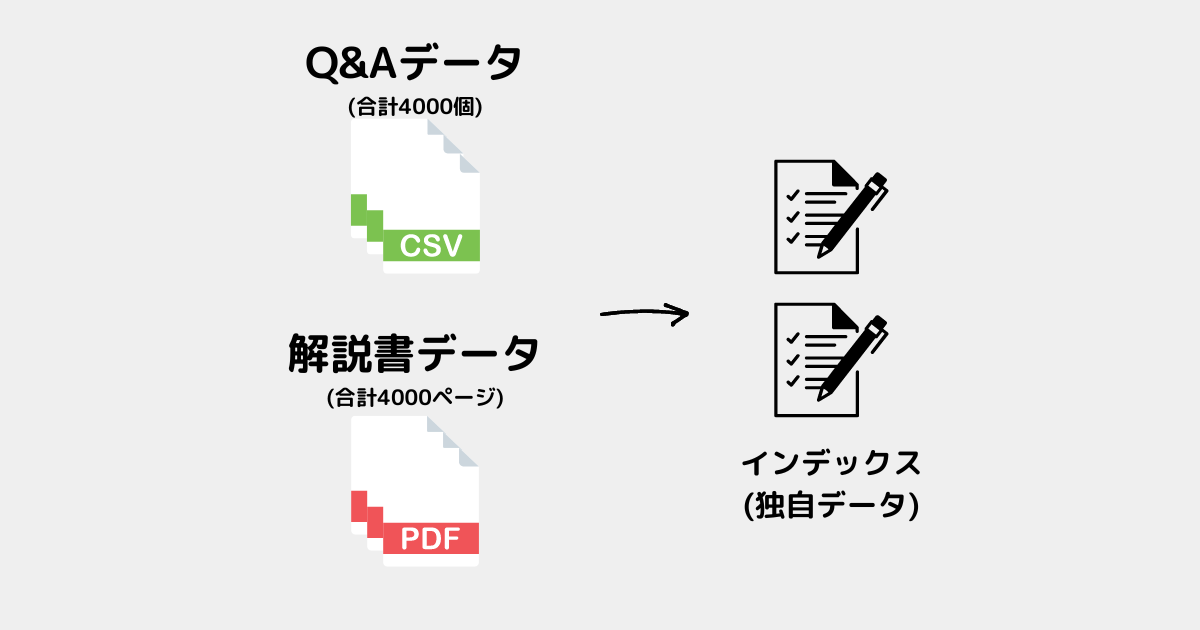
案2:CSVを1つ、PDFを1つにまとめる
✅20ファイル → 2ファイルにまとめる
(画像は簡略化のため6個にしている)
✅質問実行プログラムのイメージ
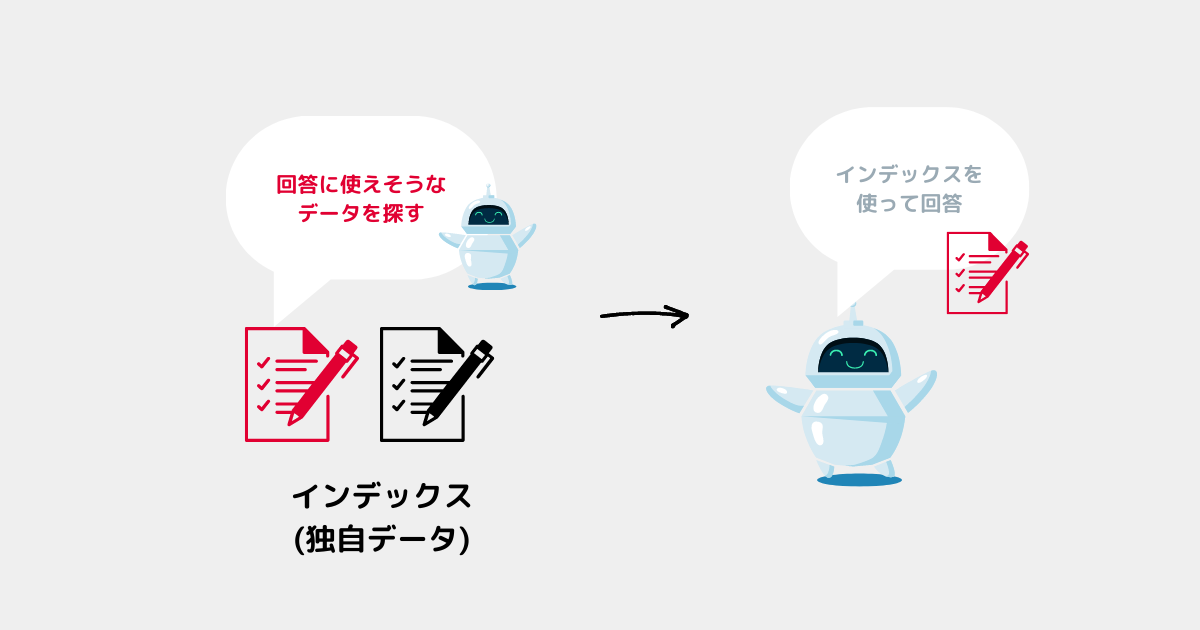
✅所感
| メリット⭕️ | デメリット❌ | 精度 |
|---|---|---|
| − | どちらのファイルに答えがあるかAIに探してもらうのが難しく、関係ないデータを使ってしまうことが多い。 | ❌ |
✅考察
案3:すべてのファイルを1つにまとめる
おそらくこれが一番オーソドックスな方法!
✅20ファイル → 1ファイルにまとめる
(画像は簡略化のため6個にしている)
✅質問実行プログラムのイメージ
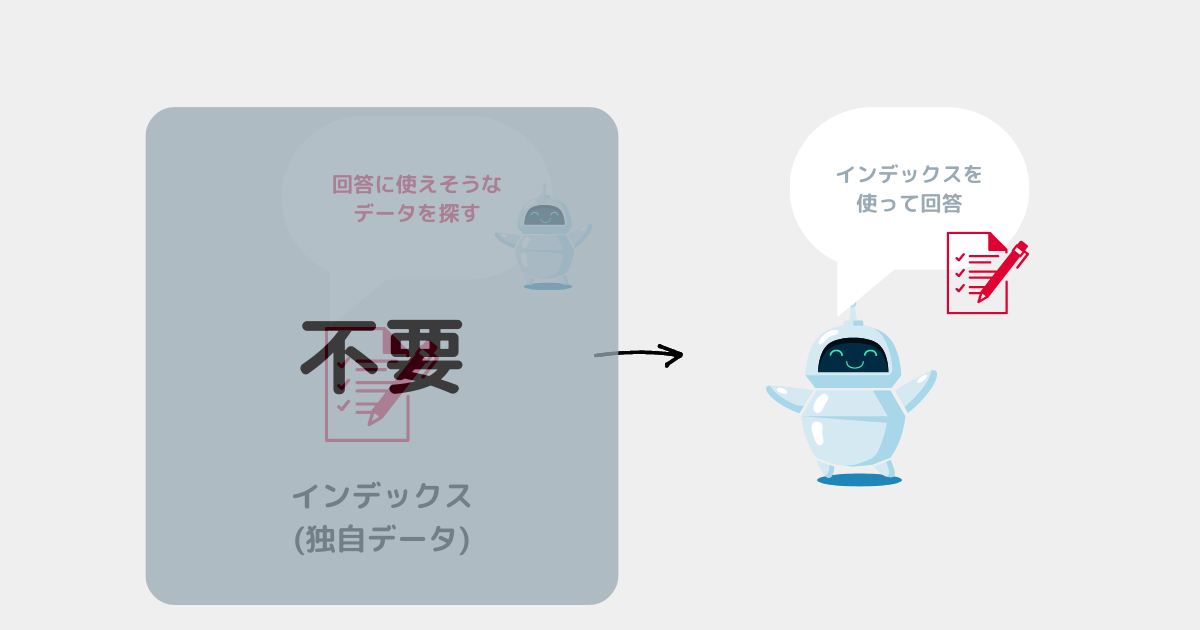
✅所感
| メリット⭕️ | デメリット❌ | 精度 |
|---|---|---|
| ・どのファイルに答えがあるか探す処理が不要になった。 ・ファイル間で重複した内容がなくなった。 | 正しい情報を使ってくれず正確な回答にならない。 | ❌ |
✅考察
案4:CSVとPDFの同じカテゴリーを1つにまとめる
✅20ファイル → 10ファイルにして重複した内容を1つのファイル内にまとめる
(画像は簡略化のため6個にしている)
✅質問実行プログラムのイメージ
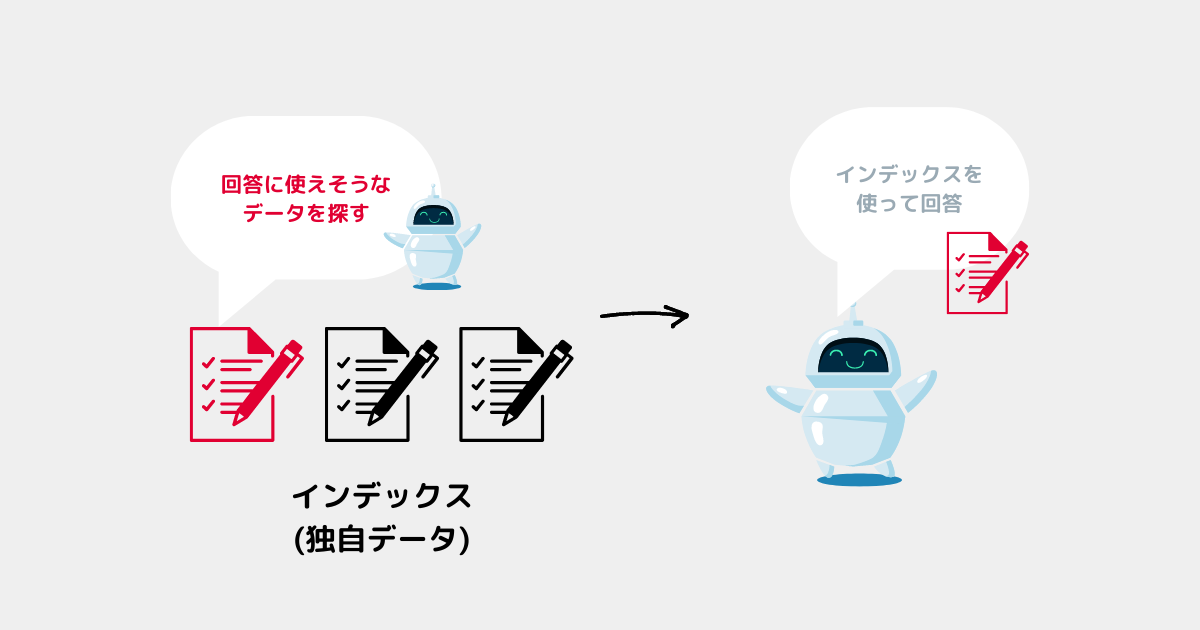
✅所感
| メリット⭕️ | デメリット❌ | 精度 |
|---|---|---|
| ・ファイルを意味のある塊(カテゴリー毎)で分けられた。 ・ファイル間で重複した内容がなくなった。 | どのファイルに答えがあるかAIに探してもらうのが少し簡単になったが、まだ関係ないデータを使うことがある。 | 🔺 |
✅考察
【補足】その他気をつけたこと
独自データの中でそのまま使うとまずそうな点は事前に修正した✅
CSVデータは1列にまとめる
Q&Aのデータ(CSV)はQ列とA列の2列に分かれていた。
(解決策)
Excelやスプレッドシートを使って1列にまとめた。
修正前
| Q | A |
|---|---|
| <p>質問テスト1</p> | <p>回答テスト1</p> |
| <p>質問テスト2</p> | <p>回答テスト2</p> |
修正後
| id | html |
|---|---|
| 1 | Q:<p>質問テスト1</p> A:<p>回答テスト1</p> |
| 2 | Q:<p>質問テスト2</p> A:<p>回答テスト2</p> |
不要なHTMLタグは削除する
CSVデータの中身がHTML形式だった。
HTMLタグは学習データとして不要💦
(解決策)
HTMLタグを除去する処理を作成した。
docs.map((row) => {
// 正規表現でHTMLタグを除去
row.pageContent = row.pageContent.replace(/<([^'">]|"[^"]*"|'[^']*')*>/g,'');
row.pageContent = decodeHTMLSpecialWord( row.pageContent );
});HTML特殊文字はアンエスケープしておく
CSVデータからHTMLタグを削除したが、まだ&などのHTML特殊文字が残っていた💦
(解決策)
& → & のように特殊文字を置換する関数を作成した。
// HTML特殊文字をアンエスケープ
function decodeHTMLSpecialWord(str: string): string {
return str
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/,/g, ",")
.replace(/./g, ".")
.replace(/:/g, ":")
.replace(/;/g, ";")
.replace(/'/g, "'")
.replace(/&ldquor/g, "„")
.replace(/&prime/g, "′")
.replace(/&Prime/g, "″")
.replace(/&tprime/g, "‴")
.replace(/&qprime/g, "⁗")
.replace(/•/g, "•")
.replace(/¨/g, "¨")
.replace(/&hellip/g, "…")
.replace(///g, "/")
.replace(/\/g, "\\")
.replace(/|/g, "|")
.replace(/¦/g, "¦")
.replace(/(/g, "(")
.replace(/)/g, ")")
.replace(/[/g, "[")
.replace(/]/g, "]")
.replace(/{/g, "{")
.replace(/}/g, "}")
.replace(/&lsaquo/g, "‹")
.replace(/&rsaquo/g, "›")
.replace(/«/g, "«")
.replace(/»/g, "»")
.replace(/‰/g, "‰")
.replace(/‱/g, "‱")
.replace(/ª/g, "ª")
.replace(/°/g, "°")
.replace(/µ/g, "µ")
.replace(/ /g, " ")
.replace(/©/g, "©")
.replace(/‘/g, "‘")
.replace(/’/g, "’")
.replace(/“/g, "“")
.replace(/”/g, "”")
.replace(/Α/g, "Α")
.replace(/α/g, "α")
.replace(/Β/g, "Β")
.replace(/β/g, "β")
.replace(/Γ/g, "Γ")
.replace(/γ/g, "γ")
.replace(/Δ/g, "Δ")
.replace(/δ/g, "δ")
.replace(/Ε/g, "Ε")
.replace(/ε/g, "ε")
.replace(/Ζ/g, "Ζ")
.replace(/ζ/g, "ζ")
.replace(/Η/g, "Η")
.replace(/η/g, "η")
.replace(/Θ/g, "Θ")
.replace(/θ/g, "θ")
.replace(/Ι/g, "Ι")
.replace(/ι/g, "ι")
.replace(/Κ/g, "Κ")
.replace(/κ/g, "κ")
.replace(/Λ/g, "Λ")
.replace(/λ/g, "λ")
.replace(/Μ/g, "Μ")
.replace(/μ/g, "μ")
.replace(/Ν/g, "Ν")
.replace(/ν/g, "ν")
.replace(/Ξ/g, "Ξ")
.replace(/ξ/g, "ξ")
.replace(/Ο/g, "Ο")
.replace(/ο/g, "ο")
.replace(/Π/g, "Π")
.replace(/π/g, "π")
.replace(/Ρ/g, "Ρ")
.replace(/ρ/g, "ρ")
.replace(/Σ/g, "Σ")
.replace(/σ/g, "σ")
.replace(/Τ/g, "Τ")
.replace(/τ/g, "τ")
.replace(/Υ/g, "Υ")
.replace(/υ/g, "υ")
.replace(/Φ/g, "Φ")
.replace(/φ/g, "φ")
.replace(/Χ/g, "Χ")
.replace(/χ/g, "χ")
.replace(/Ψ/g, "Ψ")
.replace(/ψ/g, "ψ")
.replace(/Ω/g, "Ω")
.replace(/ω/g, "ω")
.replace(/`/g, "`");
};【補足】完成したコード
動作イメージ
同じカテゴリーの独自データ2つ「dataA.csv」と「dataA.pdf」から、1つのインデックス「dataA」を作る。
|
|----dataA.csv(独自データ)
|----dataA.pdf(独自データ)
|
|----index
| |
| |----dataA(🆕CSV+PDFから作られたインデックス)make_index.ts
// ----------------------------------------------------------------
// HTML特殊文字をアンエスケープ
// ----------------------------------------------------------------
function decodeHTMLSpecialWord(str: string): string {
return str
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, '"')
.replace(/'/g, "'")
.replace(/,/g, ",")
.replace(/./g, ".")
.replace(/:/g, ":")
.replace(/;/g, ";")
.replace(/'/g, "'")
.replace(/&ldquor/g, "„")
.replace(/&prime/g, "′")
.replace(/&Prime/g, "″")
.replace(/&tprime/g, "‴")
.replace(/&qprime/g, "⁗")
.replace(/•/g, "•")
.replace(/¨/g, "¨")
.replace(/&hellip/g, "…")
.replace(///g, "/")
.replace(/\/g, "\\")
.replace(/|/g, "|")
.replace(/¦/g, "¦")
.replace(/(/g, "(")
.replace(/)/g, ")")
.replace(/[/g, "[")
.replace(/]/g, "]")
.replace(/{/g, "{")
.replace(/}/g, "}")
.replace(/&lsaquo/g, "‹")
.replace(/&rsaquo/g, "›")
.replace(/«/g, "«")
.replace(/»/g, "»")
.replace(/‰/g, "‰")
.replace(/‱/g, "‱")
.replace(/ª/g, "ª")
.replace(/°/g, "°")
.replace(/µ/g, "µ")
.replace(/ /g, " ")
.replace(/©/g, "©")
.replace(/‘/g, "‘")
.replace(/’/g, "’")
.replace(/“/g, "“")
.replace(/”/g, "”")
.replace(/Α/g, "Α")
.replace(/α/g, "α")
.replace(/Β/g, "Β")
.replace(/β/g, "β")
.replace(/Γ/g, "Γ")
.replace(/γ/g, "γ")
.replace(/Δ/g, "Δ")
.replace(/δ/g, "δ")
.replace(/Ε/g, "Ε")
.replace(/ε/g, "ε")
.replace(/Ζ/g, "Ζ")
.replace(/ζ/g, "ζ")
.replace(/Η/g, "Η")
.replace(/η/g, "η")
.replace(/Θ/g, "Θ")
.replace(/θ/g, "θ")
.replace(/Ι/g, "Ι")
.replace(/ι/g, "ι")
.replace(/Κ/g, "Κ")
.replace(/κ/g, "κ")
.replace(/Λ/g, "Λ")
.replace(/λ/g, "λ")
.replace(/Μ/g, "Μ")
.replace(/μ/g, "μ")
.replace(/Ν/g, "Ν")
.replace(/ν/g, "ν")
.replace(/Ξ/g, "Ξ")
.replace(/ξ/g, "ξ")
.replace(/Ο/g, "Ο")
.replace(/ο/g, "ο")
.replace(/Π/g, "Π")
.replace(/π/g, "π")
.replace(/Ρ/g, "Ρ")
.replace(/ρ/g, "ρ")
.replace(/Σ/g, "Σ")
.replace(/σ/g, "σ")
.replace(/Τ/g, "Τ")
.replace(/τ/g, "τ")
.replace(/Υ/g, "Υ")
.replace(/υ/g, "υ")
.replace(/Φ/g, "Φ")
.replace(/φ/g, "φ")
.replace(/Χ/g, "Χ")
.replace(/χ/g, "χ")
.replace(/Ψ/g, "Ψ")
.replace(/ψ/g, "ψ")
.replace(/Ω/g, "Ω")
.replace(/ω/g, "ω")
.replace(/`/g, "`");
};
// ----------------------------------------------------------------
// CSVからドキュメントを作成(汎用的な関数)
// ----------------------------------------------------------------
async function make_document_from_csv(
csvPath : string, // ドキュメントの元データのパス
csvColumn : string, // ドキュメントに使用するカラム名
bDelHtml : boolean = false, // CSV内にあるHTMLタグを除去するか
bSplit : boolean = true, // テキストを分割するか
chunkStrSize : number = 500, // 分割する文字数
)
{
// ドキュメントの読み込み
const loader = new CSVLoader( csvPath, csvColumn );
let docs;
if ( bSplit ){
// テキスト分割あり
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: chunkStrSize });
docs = await loader.loadAndSplit(textSplitter);
}
else{
// テキスト分割なし
docs = await loader.load();
}
// HTMLタグを除去する
if ( bDelHtml ){
docs.map((row) => {
row.pageContent = row.pageContent.replace(/<([^'">]|"[^"]*"|'[^']*')*>/g,'');
row.pageContent = decodeHTMLSpecialWord( row.pageContent );
});
}
return docs;
};
// ----------------------------------------------------------------
// PDFからドキュメントを作成(汎用的な関数)
// ----------------------------------------------------------------
async function make_document_from_pdf (
pdfPath : string, // ドキュメントの元データのパス
bDelHtml : boolean = false, // PDF内にあるHTMLタグを除去するか
bSplit : boolean = true, // テキストを分割するか
chunkStrSize : number = 500, // 分割する文字数
): Promise<any>
{
// ドキュメントの読み込み
const loader = new PDFLoader( pdfPath );
let docs;
if ( bSplit ){
// テキスト分割あり
const textSplitter = new RecursiveCharacterTextSplitter({ chunkSize: chunkStrSize });
docs = await loader.loadAndSplit(textSplitter);
}
else{
// テキスト分割なし
docs = await loader.load();
}
// HTMLタグを除去する
if ( bDelHtml ){
docs.map((row) => {
row.pageContent = row.pageContent.replace(/<([^'">]|"[^"]*"|'[^']*')*>/g,'');
row.pageContent = decodeHTMLSpecialWord( row.pageContent );
});
}
return docs;
};
// ----------------------------------------------------------------
// インデックス作成
// ----------------------------------------------------------------
async function main() {
// CSVのドキュメント
const docs_csv = await make_document_from_csv( "dataA.csv", "html", true, false );
// PDFのドキュメント
const docs_pdf = await make_document_from_pdf( "dataA.pdf", false, true );
// ドキュメントを結合
const docs = docs_csv.concat( docs_pdf );
// インデックス作成
const vectorStore = await HNSWLib.fromDocuments( docs, new OpenAIEmbeddings() );
await vectorStore.save( "index/dataA" );
}最後の
make_document_from_csvとmake_document_from_pdfの第一引数だけ変えれば使える✅(このコードのポイント)
✅2つ以上のファイルから1つのインデックスを生成
✅ファイル内のHTMLタグを除去可能
make_document_from_csvとmake_document_from_pdfの引数でON、OFFを変えられる!✅テキスト分割の設定が自由
make_document_from_csvとmake_document_from_pdfの引数で設定可能!次回
今回はここまで!
試した中では「案4:CSVとPDFの同じカテゴリーを1つにまとめる」が一番よさそうだった!
次回はエージェントを使った質問プログラムでもっと精度を上げる〜🙌