

概要
ChatGPTのAPIを使う場合、Web上のデータだけでなく独自の情報を回答してもらうことができる。
こんなことができる。
✅社内の情報を学習させ、社内用チャットボットを作る。
✅Q&Aデータを学習させ、Q&Aチャットボットを作る。
✅メールの件名と本文を学習させ、自動分類システムを作る。など
2つの方法
独自の情報を回答してもらうには2つの方法がある。
ファインチューニング(今回説明する方法)
Open AIのモデルをトレーニングして独自のモデルを作る方法。
⭕️一度トレーニングすれば次回以降は質問が短く済みAPI利用料金も抑えられる。
⭕️学習データが多くてもプロンプトが長くならない。
❌学習させる手間がかかる。
❌トレーニングで大量のデータを読み込ませるため、最初にお金がかかる。
❌使用できるモデルが限られている。
トレーニングに料金がかかるが、長期的に運用する場合は十分実用的。
(2023/11/7現在)
比較的新しいモデル「gpt-3.5-turbo-1006」が利用可能になっている。
かなり使いやすくなってきている!
プロンプトに独自の情報を含める
モデルを学習させる以外にも、質問文の中に「前提知識を与えて質問する」という方法もある。
⭕️質問文を工夫するだけなので簡単。
⭕️準備もほとんどいらず初期投資も不要。
⭕️多くのモデルに対応している。
❌毎回の質問が少し長くなるため、API利用料も少し増える。
→ただしLangChainを使えば質問に全データ入れる必要はなくなる!
❌プロンプトが長くなると毎回の処理に少し負担がかかる。
様々なモデルを使えることが強み。
詳細は以下を参照
流れ
ツール(OpenAI CLI)のインストール
学習データの用意や、モデルの学習で使用するツール✅
以下の手順でツール(OpenAI CLI)をインストールできる。
- OpenAI CLIを使うためPythonをインストールする。
(インストール済みなら不要)
- pipコマンドでOpenAI CLIをインストールする。
pip install --upgrade openai
- exportコマンドで環境変数にAPIキーを設定する。
export OPENAI_API_KEY="<OPENAI_API_KEY>"※exportコマンドによる環境変数は一度ターミナルやコマンドプロンプトを閉じると削除されるため、次回起動時に再度同じコマンドを実行する必要がある。詳細はこちらで解説している。
学習データを用意
独自にカスタマイズするためには、もちろん学習データが必要。
学習データの用意方法は以下のとおり。
学習データのフォーマット
学習データはJSONLファイル(*1)にしておくこと✅
(*1)JSONLとは
複数のJSONファイルを1つに集めたもの。
例:3つのJSONファイルをJSONLファイルにする。
{
"name": "John",
"age": 30,
"city": "New York"
}{
"name": "Alice",
"age": 25,
"city": "San Francisco"
}{
"name": "Bob",
"age": 40,
"city": "London"
}👇JSONLにする。1行=1JSONファイル。
{"name": "John", "age": 30, "city": "New York"}
{"name": "Alice", "age": 25, "city": "San Francisco"}
{"name": "Bob", "age": 40, "city": "London"}具体的には以下のような形式。
{"prompt": "製品Aの価格は?\n\n###\n\n", "completion": " 1500円です。"}
{"prompt": "製品Bの価格は?\n\n###\n\n", "completion": " 3000円です。"}
{"prompt": "製品Aの特徴は?\n\n###\n\n", "completion": " 安価なのに必要最低限の機能が一通り揃っており、コスパに優れた製品です。"}
...※promptの最後に、区切り文字\n\n###\n\nを付けておく。
※completionの最初に、半角スペースを付けておく。
キーは"prompt"と"completion"の2種類。
| キー名 | 値 |
|---|---|
| prompt | 質問を記載する。 |
| completion | 回答を記載する |
学習データの簡単な作り方
最終的にJSONL形式の学習データが必要。
「スプレッドシート」→「CSV」→「JSONL」の流れで変換していく✅
【手順1】スプレッドシートに「質問」「回答」をまとめる
学習させたいデータをスプレッドシートにまとめる✅
- A列「prompt」質問を入力する。
- B列「completion」回答を入力する。

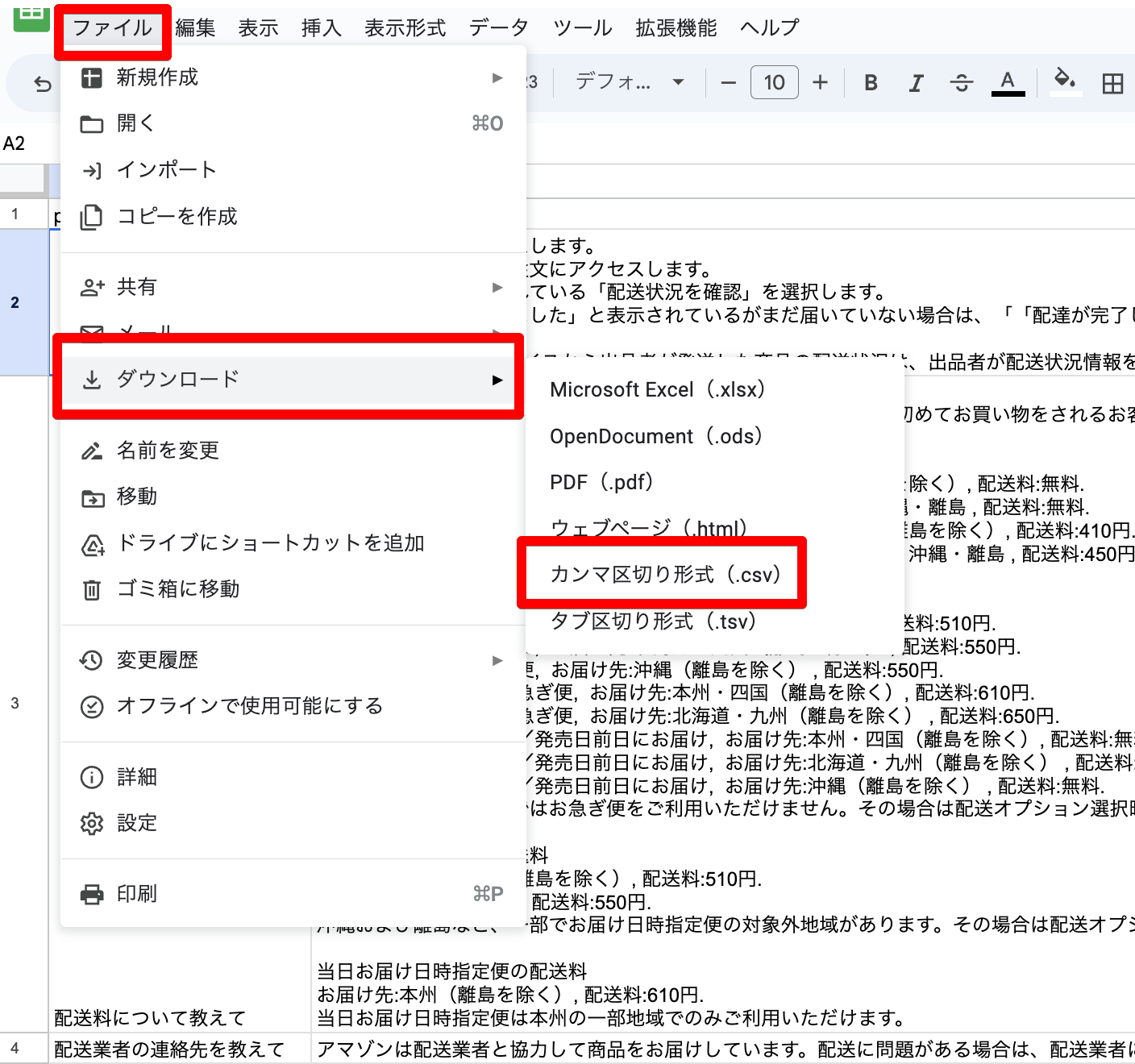
【手順2】スプレッドシートからCSVを出力する
[ファイル−ダウンロード−カンマ区切り形式(.csv)]でCSVを出力する✅
【手順3】CSVをJSONLに変換する
公式からCSVをJSONLに変換するツール(OpenAI CLI)が提供されている。
以下のコマンドでCSVをJSONLに変換できる✅
openai tools fine_tunes.prepare_data -f CSVファイルのパス例
openai tools fine_tunes.prepare_data -f /Users/example_user/Downloads/test.csv【エラー対策】
zsh: command not found: openai
zsh: permission denied: openai
opneaiコマンドが使えない場合の対処方法。
まず以下のコマンドでOpenAI CLIがどこにあるか確認する。
pip show openai実行結果(Locationを見るとインストール先が分かる)
Name: openai
Version: 0.27.4
Summary: Python client library for the OpenAI API
Home-page: https://github.com/openai/openai-python
Author: OpenAI
Author-email: support@openai.com
License:
Location: /Users/example_user/Library/Python/3.9/lib/python/site-packages
Requires: tqdm, aiohttp, requests
Required-by:Locationの「lib」ではなく「bin」フォルダにopenaiが存在することを確認する。
例:/Users/example_user/Library/Python/3.9/bin/openai
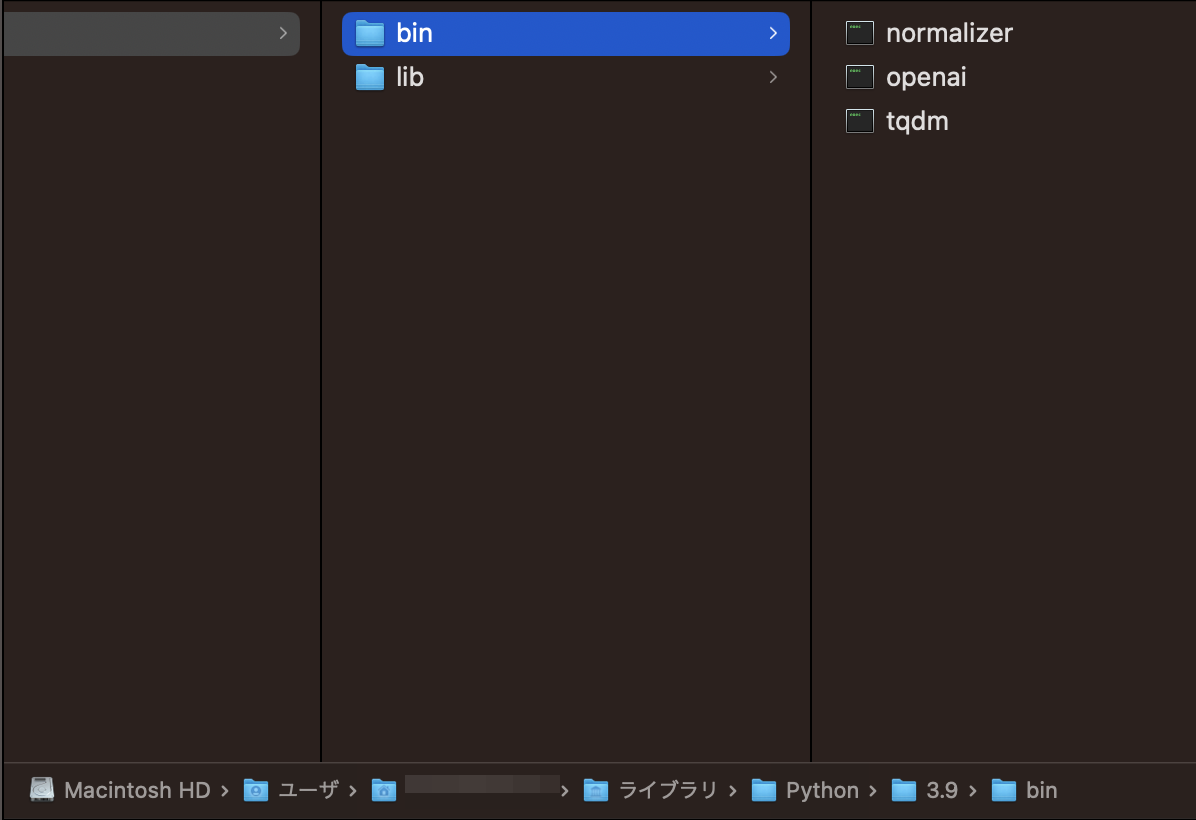
binフォルダを環境変数に追加する。
export PATH=$PATH:/Users/example_user/Library/Python/3.9/bin
【エラー対策】
OpenAI error:missing `pandas`
This feature requires additional dependencies:$ pip install openai[datalib]
openaiコマンドは使えるようになったが実行時にエラーが出る場合の対処方法。
pandasがインストールされていないのでインストールすればOK
pip install pandas学習したモデルの生成
学習データが準備できたら、実際にファインチューニングする。
学習モデルを生成する
コマンド1つで「学習したモデル」を生成できる✅
openai api fine_tunes.create -t JSONLファイルのパス -m ベースにするモデル例
openai api fine_tunes.create -t /Users/example_user/Downloads/test.jsonl -m davinci以下は自分の環境に合わせて変更する。
✅JSONLファイルのパス
事前に用意した学習データのパスを指定する。
✅ベースにするモデル
カスタマイズのベースになるモデルを指定する。
2023/4時点では以下の4つが指定できる。
| モデル | 価格(トレーニング時) | 価格(使用時) | 特徴 |
|---|---|---|---|
| Ada | $0.0004 / 1K tokens | $0.0016 / 1K tokens | 最も高速かつ低価格 |
| Babbage | $0.0006 / 1K tokens | $0.0024 / 1K tokens | 非常に高速かつ低価格なモデル |
| Curie | $0.0030 / 1K tokens | $0.0120 / 1K tokens | Davinciに次いで高機能 |
| Davinci | $0.0300 / 1K tokens | $0.1200 / 1K tokens | この中で最も高性能なモデル |
↓
(2023/8/23追記)
現在の指定できるモデルは以下のとおりになっている。
| モデル | 価格(トレーニング時) | 価格(使用時 入力) | 価格(使用時 出力) | 特徴 |
|---|---|---|---|---|
| babbage-002 | $0.0004 / 1K tokens | $0.0016 / 1K tokens | $0.0016 / 1K tokens | 非常に高速かつ低価格なモデル |
| davinci-002 | $0.0060 / 1K tokens | $0.0120 / 1K tokens | $0.0120 / 1K tokens | 高性能なモデル |
| gpt-3.5-turbo | $0.0080 / 1K tokens | $0.0120 / 1K tokens | $0.0160 / 1K tokens | この中で最も高性能なモデル |
学習モデルの名前を確認する
学習モデルを使うために、モデルの名前を知る必要がある✅
コマンドで今までに学習したモデルの一覧を表示できる。
openai api fine_tunes.list結果
{
"data": [
{
"created_at": 1682421324,
👇モデルの名前(まだ学習が完了していないためnull)
"fine_tuned_model": null,
"hyperparams": {
"batch_size": 1,
"learning_rate_multiplier": 0.1,
"n_epochs": 4,
"prompt_loss_weight": 0.01
},
👇モデルのID
"id": "ft-xxxxxxxxxxxxxxxxxxxxxxxx",
"model": "davinci",
"object": "fine-tune",
"organization_id": "org-yyyyyyyyyyyyyyyyyyyyyyyy",
"result_files": [],
👇学習の状態(学習中)
"status": "pending",
"training_files": [
{
"bytes": 13634,
"created_at": 1682421323,
"filename": "/Users/example_user/Downloads/test.jsonl",
"id": "file-xxxxxxxxxxxxxxxxxxxxxxxx",
"object": "file",
"purpose": "fine-tune",
"status": "processed",
"status_details": null
}
],
"updated_at": 1682422408,
"validation_files": []
}
],
"object": "list"
}上記を見るとstatusが「pending」でまだモデルが生成完了していないことがわかる✅
→数分後に再度確認すると以下の部分が変わり学習が完了していた。
👇モデル名
"fine_tuned_model": "davinci:ft-personal-xxxx-xx-xx-xx-xx-xx",
👇学習の状態(成功)
"status": "succeeded",学習モデルを使う
ここまでできれば普通のモデルをAPIで利用するのと同じ方法で学習モデルが使える✅
ポイントは2つ。
- リクエストで指定するモデル名を変える。
- promptの最後に区切り文字
\n\n###\n\nを付ける。
例:cURLでリクエスト
curl https://api.openai.com/v1/completions \
-H "Authorization: Bearer APIキーを入れる" \
-H "Content-Type: application/json" \
👇"prompt"の最後に区切り文字\n\n###\n\nを付ける。
👇"model"を「davinci:ft-personal-xxxx-xx-xx-xx-xx-xx」のように変える。
-d '{"prompt": "質問の文章\n\n###\n\n", "model": " 学習モデルの名前"}'細かい疑問
追加でカスタマイズできる?
以前カスタマイズしたモデルに対して、追加でカスタマイズできるか?
→できる⭕️
以下で記載されている。

学習モデルは削除できる?
OpenAI CLIのmodels.deleteで削除できる✅
openai api models.delete -i 学習モデルの名前例
openai api models.delete -i davinci:ft-personal-xxxx-xx-xx-xx-xx-xxどのような学習データを用意するのが理想的?
公式で解説されている。
ここでは公式の内容を簡単に説明する。
前提として、用途によってどのような学習データが理想か異なる✅
分類するモデルを作りたい場合
例えば以下のようなモデルを作りたい場合。
- 文章を「ポジティブ」or「ネガティブ」に分類する。
- メールを「カテゴリーA」「カテゴリーB」に分類する。
このような分類をしたい場合は以下に注意するといい✅
- 100個以上のデータを用意する。
- 回答は文章ではなく、「ポジティブ」or「ネガティブ」などの分類結果にする。
例:文章を「ポジティブ」or「ネガティブ」に分類する学習データ。
{"prompt":"Overjoyed with the new iPhone! ->", "completion":" positive"}
{"prompt":"@lakers disappoint for a third straight night https://t.co/38EFe43 ->", "completion":" negative"}※実際は2件だけでなく100件以上が理想
チャットボットなどの返答してくれるモデルを作りたい場合
例えば以下のようなモデルを作りたい場合。
- カスタマーサポートのチャットボット。
- 製品の説明をしてくれるチャットボット。
このようなチャットボットを作りたい場合は以下に注意するといい✅
- 500個以上のデータを用意する。
- 学習データは正確で質の高いものにする。
例:製品の価格を教えてくれるチャットボット
{"prompt": "製品Aの価格は?\n\n###\n\n", "completion": " 1500円です。"}
{"prompt": "製品Bの価格は?\n\n###\n\n", "completion": " 3000円です。"}
{"prompt": "製品Aの特徴は?\n\n###\n\n", "completion": " 安価なのに必要最低限の機能が一通り揃っており、コスパに優れた製品です。"}
...※実際は3件だけでなく500件以上が理想
まとめ・課題
現状は対応モデルが少ないため、まだ実用的ではないように感じた。
gpt-3.5-turboなどが対応すれば本格的に開発してみたい。
(2023/11/7現在)
比較的新しいモデル「gpt-3.5-turbo-1006」が使えて実用的になってきている😊
ただし料金が少し高いのがネック💦
| 種類 | トレーニング | 入力 | 出力 |
|---|---|---|---|
| 通常のAPI (gpt-3.5-turbo-1106) | − | $0.0010 / 1K tokens | $0.0020 / 1K tokens |
| ファインチューニング (gpt-3.5-turbo) | $0.0080 / 1K tokens | $0.0030 / 1K tokens | $0.0060 / 1K tokens |
「少しでも安く済ませたい」「最新のモデルを使いたい」という方は以下の方法が合っていそう💭
参考サイト
公式ドキュメント

公式APIリファレンス
基礎的な解説



OpenAI API の ファインチューニングガイドのまとめ

実践的な解説


