概要
✅Node.jsでスクレイピングするためのライブラリ「Puppeteer」を初めて使ったときの備忘録をまとめる😊
対象読者
- Javascript(Node.js)でスクレイピングがしたい。
- Puppeteerを初めて使う。
- コピペですぐ動かしたい。
Puppeteerって何?
✅Node.jsでブラウザを自動的に起動し、Webページのスクリーンショットを撮影したり、ページを操作したりすることができるライブラリ。
使用イメージ
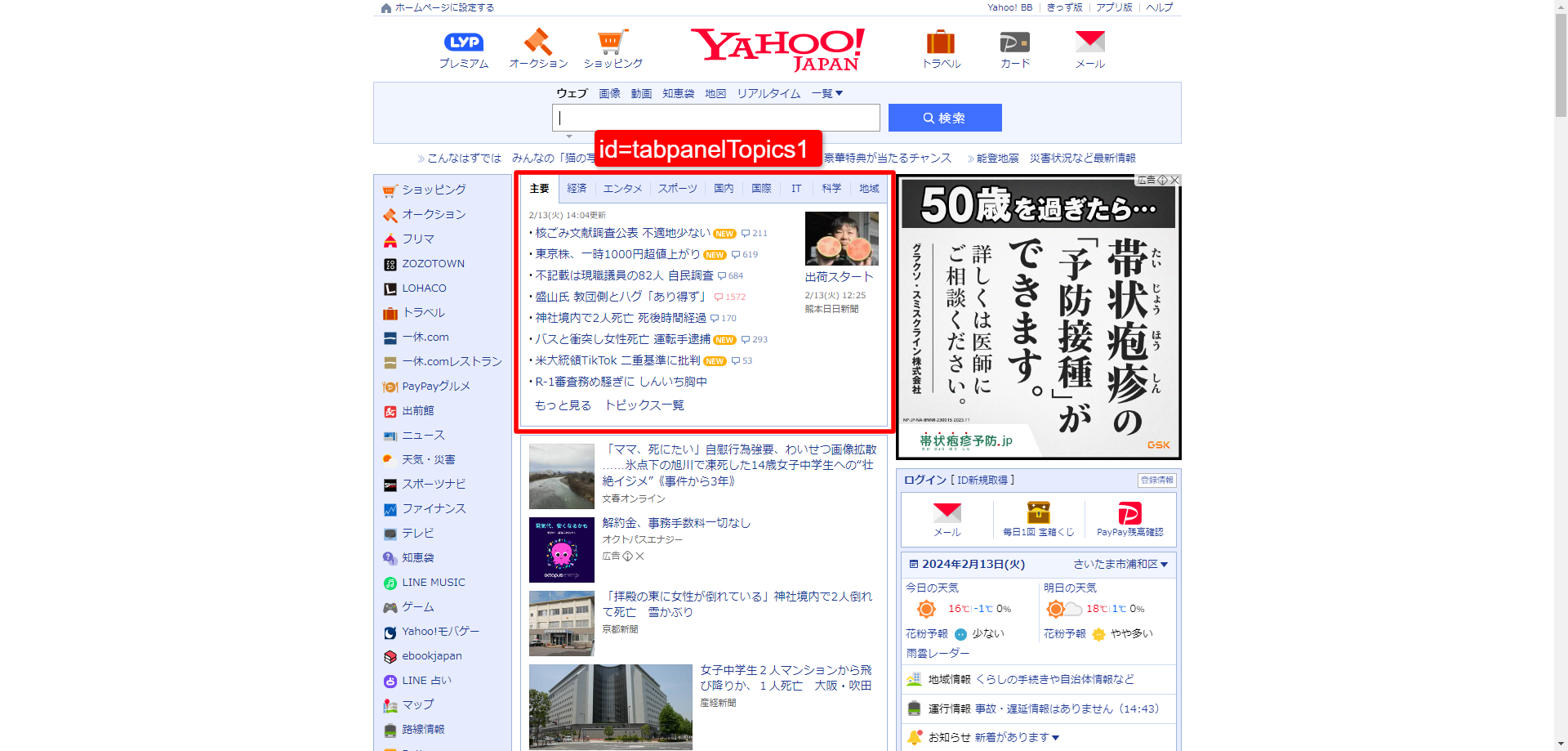
✅Yahooニュース(https://www.yahoo.co.jp/)から以下の部分を取得する。
ログインが必要なページもスクレイピングできる?
「ベーシック認証」や「ログイン」が必要なページでも対応できる!
Puppeteerのいいところ
✅ヘッドレスモード(スクレイピングするときに画面上にブラウザが出てこない)で使用できる。
→軽快なスクレイピングができる。
✅処理の流れがある程度決まっている。
→サンプルコードをコピペして少し書き換えればすぐ使える!
基本的な使い方
✅まずは最も簡単のサンプルプログラムの使い方を解説する。
やること
サンプルコード
getYahoo.js
import puppeteer from "puppeteer";
/**
* Yahooのニュースをスクレイピングします。
*/
const getYahoo = async () => {
let ret;
// Puppeteerの起動オプション設定
const LAUNCH_OPTION = {
headless: false, // ブラウザを表示するかどうか(false:ブラウザを表示する, true:ブラウザを表示しない)
};
// ----------------------------------------------------------------
// 【ステップ1】ブラウザを起動
const browser = await puppeteer.launch(LAUNCH_OPTION);
try {
// ----------------------------------------------------------------
// 【ステップ2】ページを開く
// 新しいタブを開く
const page = await browser.newPage();
// Yahooのページに移動し、DOMの読み込みが完了するまで待つ
await page.goto("https://www.yahoo.co.jp/", {
waitUntil: "domcontentloaded",
});
// ----------------------------------------------------------------
// 【ステップ3】データを取得する
// 特定の要素を取得
const element1 = await page.$("#tabpanelTopics1");
// 要素が存在する場合
if (element1) {
// 要素のテキストを取得
const text = await page.evaluate((elm) => elm.textContent, element1);
ret = text;
} else {
// 要素が見つからない場合、エラーメッセージ
ret = "Element not found";
}
} finally {
// ----------------------------------------------------------------
// 【ステップ4】ブラウザを閉じる
await browser.close();
return ret;
}
};
// 実行する
getYahoo();
// エクスポートする場合
// export default getYahoo;実行結果
✅Yahooニュースからスクレイピングした文字が取得できる。
実行結果
※スクレイピングした文字をブラウザ上に表示した場合

よく使う関数
✅上記で使用した関数、よく使う関数を紹介する。
これらを抑えておけば基本的なスクレイピングはOK!
また書き方も「普段手動でしているブラウザ操作」をそのまま関数で書いているイメージなので直感的に理解しやすい。
ブラウザを起動するpuppeteer.launch( LAUNCH_OPTION )
使用例
const browser = await puppeteer.launch({
headless: false, // ブラウザを表示するかどうか(false:ブラウザを表示する, true:ブラウザを表示しない)
});新しいタブを開くbrowser.newPage()
使用例
const page = await browser.newPage();指定したページを開くpage.goto(url, options)
使用例(https://www.yahoo.co.jp/を開く)
await page.goto("https://www.yahoo.co.jp/", {
waitUntil: "domcontentloaded", // DOMContentLoadedイベントを待つ(DOMの読み込みが完了するまで待つ)
});CSSセレクタにマッチする最初の要素を取得するpage.$(selector)
使用例(id=”mytextarea”の要素を取得する)
const element = await page.$("#mytextarea"); // document.querySelector("#mytextarea")と同じ※要素が見つからない場合は、戻り値がnullになる。
if ( !element ){
// 要素が見つからない場合の処理
}CSSセレクタにマッチする要素をすべて取得するpage.$$(selector)
使用例(class=”section”の要素をすべて取得する)
const elements = await page.$$(".section"); // document.querySelectorAll(".section")と同じinputタグなどにテキストを入力するpage.type(selector, text, options)
使用例(100ミリ秒後、id=”mytextarea”のinputタグに、'World'と入力する)
await page.type("#mytextarea", "World", {delay: 100});指定された要素をクリックするpage.click( selector, clickOptions )
使用例
await page.click("#mybutton")※厳密にはセレクタを持つ要素を取得し、必要であればスクロールして表示し、Page.mouseを使って要素の中心をクリックする。
(ボタンクリック後などに)新しいページに移動するのを待つpage.waitForNavigation( options )
使用例
await page.waitForNavigation();テキストを取得するpage.evaluate( pageFunction, args )
※厳密には第一引数で渡した関数をページ内で実行し、結果を取得する。Pageオブジェクトにテキストを取得するメソッドがないためevaluateを使う必要がある。
使用例(id=”mytextarea”の要素のテキストを取得する)
const element = await page.$("#mytextarea");
const text = await page.evaluate( elm => elm.textContent, element );応用
ベーシック認証がかかっているページ
✅page.authenticate(…)を使うだけ!
使用例
// ベーシック認証の情報を提供する
await page.authenticate({username: 'Basic 認証のユーザ名', password: 'Basic 認証のパスワード'});
// ベーシック認証がかかったページに移動する
await page.goto('Basic 認証がかかったページのURL', {waitUntil: "domcontentloaded"});【補足】Basic認証の情報を環境変数に設定する
外部に公開するような場合は機密情報はdotenvを使って環境変数に設定しておくといい。
dotenvをインストール
npm install dotenv環境変数用のファイルを作成
.env
BASIC_USER="Basic 認証のユーザ名"
BASIC_PASS="Basic 認証のパスワード"Puppeteerのコードを修正
require('dotenv').config();
await page.authenticate({username: process.env.BASIC_USER, password: process.env.BASIC_PASS});
await page.goto('Basic 認証がかかったページのURL', {waitUntil: "domcontentloaded"});これでファイルの中に機密情報を書かずに済む!
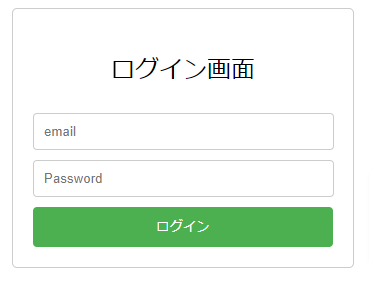
ログインが必要なページ
✅基本的な関数を組み合わせて使うだけ!
流れ
- ログインページを開く。
- ログイン情報(メールアドレス、パスワード)を入力する。
- ログインボタンをクリックする。
- 任意のページ(ログインしていないと見られないページ)に移動してスクレイピングする。
サンプルコード
import puppeteer from "puppeteer";
/**
* ○○ページをスクレイピングします。
* @returns {Promise<string>} スクレイピングした結果のテキスト、またはエラーメッセージ
*/const getHoge = async () => {
let ret;
// Puppeteerの起動オプション設定
const LAUNCH_OPTION = {
headless: false, // ブラウザを表示するかどうか(false:ブラウザを表示する, true:ブラウザを表示しない)
};
// ----------------------------------------------------------------
// 【ステップ1】ブラウザを起動
const browser = await puppeteer.launch(LAUNCH_OPTION);
try {
// ----------------------------------------------------------------
// 【ステップ2】ログインする
// 新しいタブを開く
const page = await browser.newPage();
// 1. ログインのページに移動し、DOMの読み込みが完了するまで待つ
await page.goto("ログインが必要なページのURL", {"waitUntil":"domcontentloaded"});
// 2. メールアドレスとパスワードを入力
await page.type('#email', email); // '#email'はinput要素のid属性。適宜変更。
await page.type('#password', password); // '#password'はinput要素のid属性。適宜変更。
// 3.ログインボタンをクリック
await page.click('#login'); // '#login'はログインボタンのid属性。適宜変更。
// ページ遷移が完了するまで待つ
await page.waitForNavigation();
// ----------------------------------------------------------------
// 【ステップ3】ページを開く
// 4. スクレイピングしたいページに移動し、DOMの読み込みが完了するまで待つ
await page.goto("スクレイピングしたいページのURL", {"waitUntil":"domcontentloaded"});
// ----------------------------------------------------------------
// 【ステップ3】データを取得する
// 特定の要素を取得
const element1 = await page.$("スクレイピングしたい要素"); // document.querySelectorと同じ
// 要素が存在する場合
if (element1) {
// 要素のテキストを取得
const text = await page.evaluate((elm) => elm.textContent, element1);
ret = text;
} else {
// 要素が見つからない場合、エラーメッセージ
ret = "Element not found";
}
} finally {
// ----------------------------------------------------------------
// 【ステップ4】ブラウザを閉じる
await browser.close();
return ret;
}
};
// 実行する
getHoge();
// エクスポートする場合
// export default getHoge;【ステップ2】の部分でログインしている。
(単純にinputタグにメールアドレス、パスワードを入力してログインボタンをクリックしているだけ。)
それ以外はこれまでとほぼ同じ。